pip install category_encodersJob Verifier
Purpose & Impact
The rise of fraudulent job postings has become a significant issue, leading to wasted time, lost opportunities, and potential scams targeting job seekers. Many individuals unknowingly apply to fake job listings, which can result in frustration, financial loss, and even identity theft. This AI application/data analysis tool is designed to address this problem by analyzing job postings and distinguishing between real and fraudulent listings based on the provided data. By offering insights into the prevalence of fake jobs, this tool helps job seekers make informed decisions, reducing the risk of falling victim to scams. The expected impact is substantial, as it can save job seekers valuable time, enhance trust in online job markets, and contribute to a more transparent and secure employment landscape.
Stakeholders and Beneficiaries
A fraudulent job detection tool benefits job seekers by protecting them from scams, financial loss, and wasted time, while also helping job portals maintain credibility by filtering out fake listings. Employers and recruiters can safeguard their brands from misuse, and government agencies can use the tool to combat employment fraud. Career coaches and employment agencies can ensure their clients apply to legitimate opportunities, while cybersecurity teams can leverage it to detect fraud patterns. Overall, this tool aims to enhance job market security, transparency, and trust for all stakeholders. By integrating this AI tool, portals can detect and remove fraudulent postings, enhancing trust and user satisfaction. Potential use cases include job boards using this technology to automatically vet listings before they go live and job seekers leveraging the tool to verify postings before applying. Ultimately, this solution creates a safer and more transparent job search experience for everyone involved.
The project domain falls under fraud detection in online job postings, specifically within the fields of natural language processing (NLP), machine learning, and cybersecurity. It focuses on analyzing job descriptions to identify fraudulent listings, making it relevant to areas such as employment analytics, recruitment technology, and online safety.
Data Origin & Data Source:
The data was sourced from Kaggle.com. The dataset is valuable for building a classification model to predict fraudulent job descriptions using text and meta-features.
Link to Dataset: https://www.kaggle.com/datasets/shivamb/real-or-fake-fake-jobposting-prediction
import kagglehub
import pandas as pd
# Download latest version
path = kagglehub.dataset_download("shivamb/real-or-fake-fake-jobposting-prediction")
jobs = pd.read_csv(path + "/fake_job_postings.csv")
jobs.head()Preprocessing
-
To prepare the dataset for analysis, we first addressed missing values by removing any records where the fraudulent column (our target variable) was empty. This ensures that our model has a well-defined set of labeled data for training and evaluation.
-
Since we are using an ensemble approach, we identified categorical and text-based features early in the process. This distinction is crucial as it allows us to apply appropriate feature extraction strategies tailored to each data type.
-
For categorical and text features, we replaced null values with an empty string to maintain data consistency and prevent issues during model training. This preprocessing step ensures that our machine learning pipeline can handle missing data effectively while maximizing the utility of available information.
import csv
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.ticker import LinearLocator, FormatStrFormatter
from matplotlib import rcParams
import torch_xla.core.xla_model as xm # TPU Support
# drop rows with missing values in the 'fraudulent' column
# This column is the target variable for our analysis
jobs = jobs.dropna(subset=['fraudulent'])
# replace missing values with empty strings
text_features = ['title', 'company_profile', 'description', 'requirements', 'benefits']
jobs[text_features] = jobs[text_features].fillna('')
# Identify categorical features
categorical = ['employment_type', 'required_experience', 'required_education', 'industry', 'function','department','salary_range']
#fill null categorical columns with zeros
jobs[categorical] = jobs[categorical].fillna('')jobs.head()Exploratory Analysis
print(jobs.shape)
jobs.info()jobs.describe()Our Data shows a great imablance in our dataset that could negatively impact the accuracy of our predictions. That will need to be handled
fraudulent_counts = jobs['fraudulent'].value_counts()
non_fraudulent_count = fraudulent_counts[0]
fraudulent_count = fraudulent_counts[1]
# graph the count of fraudulent and non-fraudulent job postings
plt.figure(figsize=(4, 4))
plt.title('Count of Fraudulent and Non-Fraudulent Job Postings')
plt.xticks([0, 1], ['Non-Fraudulent', 'Fraudulent'])
plt.ylabel('Count')
plt.xlabel('Job Posting Type')
plt.bar([0, 1], [non_fraudulent_count, fraudulent_count], color=['blue', 'red'])
plt.show()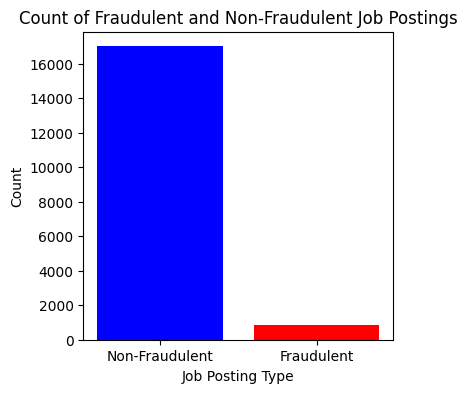
Feature Processing
Our feature selection was guided by factors that could effectively differentiate between fake and real job postings. We prioritized high-signal text fields for use in our MLP classifier, as these fields contain critical indicators of fraudulent job listings. Key text-based features include the title, where fake jobs may use exaggerated or vague wording, the company profile, which may lack details or contain suspicious descriptions, and the job description and requirements, as fraudulent listings often include generic or unusual criteria.
MLP Classifier
High-Signal Text Fields (Most Important for Fraud Detection)
- title: Some fake jobs use exaggerated or vague titles.
- company_profile: Fake jobs may lack company details or have suspicious descriptions.
- description: Key information about the job itself.
- requirements: Fake jobs may have unusual or generic requirements.
XGBoost
We identified categorical features that were less text-heavy and better suited for models like XGBoost. These include location and salary range, as well as binary indicators such as telecommuting, presence of a company logo, and whether the listing includes screening questions. Other categorical variables like employment type, required experience, required education, industry, and job function were also considered important for classification.
Categorical
- location & salary_range: Not text-heavy
- telecommuting, has_company_logo, has_questions: Binary flags
- employment_type, required_experience, required_education, industry, function: Categorical
BERT Embeddings
For feature extraction from text data, we tokenized and encoded the text using a pretrained BERT model (bert-base-uncased). We combined the relevant text columns that we identified in the previous step and converted them into dense embeddings using BERT's [CLS] token representation, allowing the model to capture meaningful contextual relationships within job descriptions.
import random
import torch
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
# set the random seed for reproducibility
random.seed(42)
# load the pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# combine releavant text columns into a single column
texts = jobs['combined_text'] = jobs[['title', 'company_profile', 'description', 'requirements', 'benefits']].fillna("").agg(' '.join, axis=1)# batch encode the texts to reduce memory load
import gc
gc.collect()
torch.cuda.empty_cache()
batch_size = 256
embeddings = []
#tried batching but memory load was too high
# switched to TPU to handle computational lode after encountering memory issues
model = model.to(xm.xla_device())
with torch.no_grad():
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
encoding = tokenizer.batch_encode_plus(
batch_texts,
truncation=True,
padding=True,
return_tensors='pt',
add_special_tokens=True
)
input_ids = encoding['input_ids'].to(xm.xla_device())
attention_mask = encoding['attention_mask'].to(xm.xla_device())
# Generate embeddings using BERT model
outputs = model(input_ids, attention_mask=attention_mask)
# get the embeddings from the last hidden state
batch_embeddings = outputs.pooler_output.cpu().cpu()
embeddings.append(batch_embeddings)
# clear memory cache
del input_ids, attention_mask, outputs
gc.collect()
torch.cuda.empty_cache()
# concatenate the embeddings from all batches
embeddings = torch.cat(embeddings, dim=0)print(embeddings.shape)SPLIT DATASET
The dataset was split into 80% training and 20% test for both categorical and text data
from sklearn.model_selection import train_test_split
#split dataset
X_train, X_test, y_train, y_test = train_test_split(embeddings, jobs['fraudulent'], test_size=0.2, random_state=42)Split Dataset on categorical data
from sklearn.model_selection import train_test_split
#split dataset
X_cat_train, X_cat_test, y_cat_train, y_cat_test = train_test_split(jobs[categorical], jobs['fraudulent'], test_size=0.2, random_state=42)Encoding Categorical Features
Target encoding was applied to categorical values by replacing each category with the mean target value (fraudulent job probability) for that category. The encoded values were then normalized to ensure consistency and improve model performance.
import category_encoders as ce
from sklearn.preprocessing import StandardScaler
#Target encoding on categorical features
target_encode = ce.TargetEncoder(cols=X_cat_train.columns.tolist())
X_cat_train_encoded = target_encode.fit_transform(X_cat_train, y_cat_train)
X_cat_test_encoded = target_encode.transform(X_cat_test)
#Normalise the encoded values
scaler = StandardScaler()
X_cat_train_scaled = scaler.fit_transform(X_cat_train_encoded)
X_cat_test_scaled = scaler.transform(X_cat_test_encoded)
print(f"Training Set Shape: {X_cat_train_scaled.shape}")
print(f"Test Set Shape: {X_cat_test_scaled.shape}")Handling Imbalanced Dataset (SMOTE)
A drawback of our dataset is that it is greatly imbalanced. A count of our values revealed that non fraudulent jobs accounted for 95% of the dataset. A logistic regression revealed a high accuracy of 96%, however a confusion matric revealed that majority of the real jobs were predicted as fraudulent despite the 96% accuracy.
jobs.fraudulent.value_counts()##Logistic Regression
Logistic regression resulted in a 90% accuracy
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
lr = LogisticRegression()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
accuracy_score(y_test, y_pred)Confusion matrix
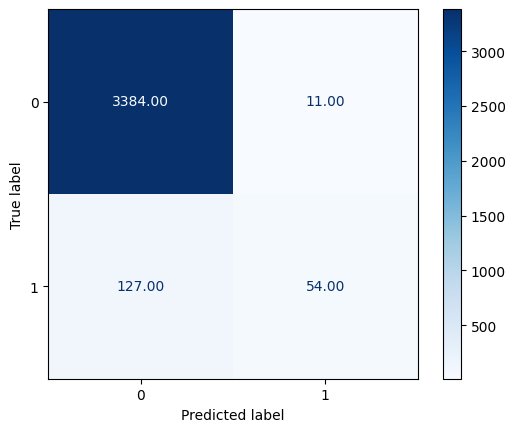
The confusion matrix revealed that the majority of the fraudulent jobs in the test set was predicted as being real, despite the high accuracy. This is a problem of using accuracy in an imbalanced dataset
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
#confusion_matrix(y_test, y_pred)
display = ConfusionMatrixDisplay.from_estimator(
lr,
X_test,
y_test,
cmap=plt.cm.Blues,
values_format=".2f",
)
##Recall Score
The recall score which is the true positive rate (TPR), or the proportion of all actual positives that were classified correctly as positives. We used the recall score evaluation metric because our dataset is very imbalances and number of actual positives is very low, recall is a more meaningful metric than accuracy because it measures the ability of the model to correctly identify all positive instances.
The logistic regression model produces a recall of 0.28 which means our model is capturing only 28% of the actual positive cases.
This low recall suggests the model is missing a significant number of fake job postings.
from sklearn.metrics import recall_score
recall_score(y_test, y_pred)SMOTE (Synthetic Minority Over-sampling Technique)
To handle our imblances data set we chose the Synthetic Minority Over-sampling Technique or SMOTE for short
SMOTE is an over-sampling method that synthesizes new examples from the existing minority sample. This is a type of data augmentation for the minority class, it does this by selecting examples that are close in the feature space, drawing a line between the examples in the feature space and drawing a new sample at a point along that line.
pip install imblearnfrom imblearn.over_sampling import SMOTE
y_train.value_counts()SMOTE was fitted to both the categorical and text dataset split
smt = SMOTE()
X_cat_train_resampled, y_cat_train_resampled = smt.fit_resample(X_cat_train_scaled, y_cat_train)
X_train, y_train = smt.fit_resample(X_train, y_train)The count now revealed that both classes contains the same amount of data.
np.bincount(y_cat_train)
np.bincount(y_cat_train_resampled)After fitting smote our Logstic Regression Model produced an accuracy of 82% and a much higher recall of 82% which acheived our desired outcome of improving the recall score.
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(f"Recall: {recall_score(y_test, y_pred)}")Multi-layer Perceptron (MLP) Classifer
The MLP classifier optimizes the log-loss function using LBFGS or stochastic gradient descent.It was chosen because of its effectiveness with classification problems, including text classification. A max iteration of 300 and random_state of 1 was selected.
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
clf = MLPClassifier(random_state=1, max_iter=300)
clf.fit(X_train, y_train)pip install tabulateEvaluate Model
from sklearn.metrics import accuracy_score, cohen_kappa_score, precision_score, recall_score
from sklearn.base import clone
from tabulate import tabulate
# To tabulate evluation metrics and compare models with reusable code
def evaluate_model(model, X_test, Y_test):
y_pred = model.predict(X_test)
acc = accuracy_score(y_pred, Y_test)
kappa = cohen_kappa_score(y_pred, Y_test)
precision = precision_score(y_pred, Y_test, average='weighted')
recall = recall_score(y_pred, Y_test, average='weighted')
return model, acc, kappa, precision, recallAn evaluation of our MLP classifer produced: a high accuray of 0.967 and recall of 0.967
Model Accuracy Kappa Precision Recall
MLPClassifier(max_iter=300, 0.966723 0.65644 0.966469 0.966723 random_state=1)
metrics = []
metrics.append(evaluate_model(clf, X_test, y_test))
headers = ["Model", "Accuracy", "Kappa", "Precision", "Recall"]
markdown_table = tabulate(metrics, headers=headers, tablefmt="github")
print(markdown_table)| Model | Accuracy | Kappa | Precision | Recall |
|---|---|---|---|---|
| MLPClassifier(max_iter=300, random_state=1) | 0.955257 | 0.608216 | 0.951051 | 0.955257 |
pip install xgboostXGBoost
#XGBoost
from sklearn.metrics import explained_variance_score
import xgboost as xgb
xgb_clf = xgb.XGBClassifier(n_estimators=75, subsample=0.75, max_depth=7, device='cpu')
xgb_clf.fit(X_cat_train_resampled, y_cat_train_resampled)metric = evaluate_model(xgb_clf, X_cat_test_scaled, y_cat_test)
headers = ["Model", "Accuracy", "Kappa", "Precision", "Recall"]
markdown_table = tabulate([metric], headers=headers, tablefmt="github")
print(markdown_table)| Model | Accuracy | Kappa | Precision | Recall |
|---|---|---|---|---|
| XGBClassifier(base_score=None, booster=None, callbacks=None, | ||||
| colsample_bylevel=None, colsample_bynode=None, | ||||
| colsample_bytree=None, device='cpu', early_stopping_rounds=None, | ||||
| enable_categorical=False, eval_metric=None, feature_types=None, | ||||
| feature_weights=None, gamma=None, grow_policy=None, | ||||
| importance_type=None, interaction_constraints=None, | ||||
| learning_rate=None, max_bin=None, max_cat_threshold=None, | ||||
| max_cat_to_onehot=None, max_delta_step=None, max_depth=7, | ||||
| max_leaves=None, min_child_weight=None, missing=nan, | ||||
| monotone_constraints=None, multi_strategy=None, n_estimators=75, | ||||
| n_jobs=None, num_parallel_tree=None, ...) | 0.855984 | 0.275947 | 0.838058 | 0.855984 |
Gradient Tuning of XGBoost Model
We can use the grid search capability in scikit-learn to evaluate the effect on logarithmic loss of training a gradient boosting model with different learning rate values, max depth as well as the number of estimators
Max Depth Tuning
-
To optimize our model, we adjusted the size of the decision trees. Shallow trees perform poorly as they capture minimal details of the problem and are often considered weak learners. In contrast, deeper trees tend to capture excessive details, leading to overfitting, which reduces their ability to generalize to new data.
-
We utilized GridSearch to assess the performance of different configurations, testing maximum tree depths of 1, 3, 5, 7, 9, and 11.
-
Each of the five configurations was evaluated using 10-fold cross-validation, resulting in the construction of 60 models.
import matplotlib.pyplot as plt
%matplotlib inline# Tune max_depth
from pandas import read_csv
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
# grid search
max_depth = range(1, 15, 2)
print(max_depth)
param_grid = dict(max_depth=max_depth)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(xgb_clf, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold, verbose=1)
grid_result = grid_search.fit(X_cat_train_resampled, y_cat_train_resampled)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
# plot
plt.errorbar(max_depth, means, yerr=stds)
plt.title("XGBoost max_depth vs Log Loss")
plt.xlabel('max_depth')
plt.ylabel('Log Loss')
plt.show()
# plt.savefig('max_depth.png')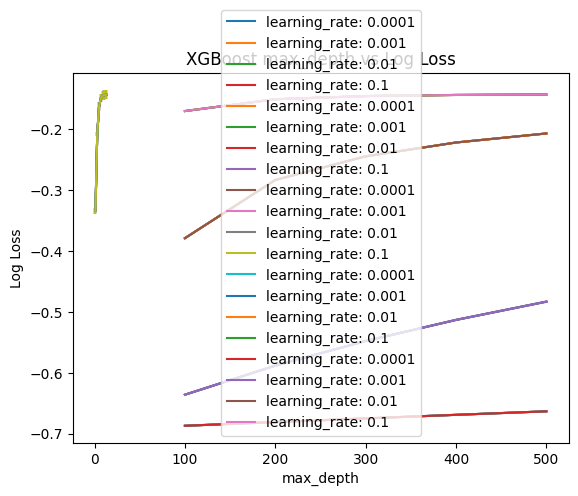
Tune learning rate and number of trees
To evaluate the learning rate and number of trees optimal for the model, we evaluated a grid of parameter pairs, varying the number of decision trees from 100 to 500 and adjusting the learning rate on a log10 scale from 0.0001 to 0.1: Smaller learning rates typically require a greater number of trees to achieve optimal performance.
- n_estimators = [100, 200, 300, 400, 500]
- learning_rate = [0.0001, 0.001, 0.01, 0.1]
With 5 variations of n_estimators and 4 variations of learning_rate, each combination will be assessed using 10-fold cross-validation. This results in training and evaluating a total of 200 XGBoost models (4 × 5 × 10).
pip install numpyn_estimators = [100, 200, 300, 400, 500]
learning_rate = [0.0001, 0.001, 0.01, 0.1]
print(learning_rate)
param_grid = dict(learning_rate=learning_rate, n_estimators=n_estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(xgb_clf, param_grid, scoring="neg_log_loss", n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(X_cat_train_resampled, y_cat_train_resampled)
# summarize results
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
# plot results
scores = np.array(means).reshape(len(learning_rate), len(n_estimators))
for i, value in enumerate(learning_rate):
plt.plot(n_estimators, scores[i], label='learning_rate: ' + str(value))
plt.legend()
plt.xlabel('n_estimators')
plt.ylabel('Log Loss')
plt.show()
plt.savefig('learning_rate.png')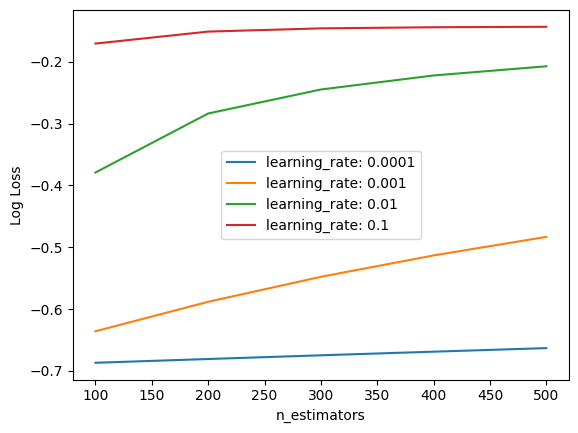
Evaluate XGBoost
Here we evaluated the XGBOOST model with differnt parameters to see which was optimal.
metric = []
metric.append(evaluate_model(xgb.XGBClassifier(n_estimators=400,learning_rate=0.1, subsample=0.75, max_depth=9, device='cpu').fit(X_cat_train_resampled, y_cat_train_resampled), X_cat_test_scaled, y_cat_test))
metric.append(evaluate_model(xgb.XGBClassifier(n_estimators=300,learning_rate=0.4, subsample=0.75, max_depth=9, device='cpu').fit(X_cat_train_resampled, y_cat_train_resampled), X_cat_test_scaled, y_cat_test))
metric.append(evaluate_model(xgb.XGBClassifier(n_estimators=500,learning_rate=0.1, subsample=0.75, max_depth=11, device='cpu').fit(X_cat_train_resampled, y_cat_train_resampled), X_cat_test_scaled, y_cat_test))
headers = ["Model", "Accuracy", "Kappa", "Precision", "Recall"]
markdown_table = tabulate(metric,headers=headers, tablefmt="github")
print(markdown_table)| Model | Accuracy | Kappa | Precision | Recall |
|---|---|---|---|---|
| XGBClassifier(base_score=None, booster=None, callbacks=None, | ||||
| colsample_bylevel=None, colsample_bynode=None, | ||||
| colsample_bytree=None, device='cpu', early_stopping_rounds=None, | ||||
| enable_categorical=False, eval_metric=None, feature_types=None, | ||||
| feature_weights=None, gamma=None, grow_policy=None, | ||||
| importance_type=None, interaction_constraints=None, | ||||
| learning_rate=0.1, max_bin=None, max_cat_threshold=None, | ||||
| max_cat_to_onehot=None, max_delta_step=None, max_depth=9, | ||||
| max_leaves=None, min_child_weight=None, missing=nan, | ||||
| monotone_constraints=None, multi_strategy=None, n_estimators=400, | ||||
| n_jobs=None, num_parallel_tree=None, ...) | 0.858221 | 0.287195 | 0.842688 | 0.858221 |
| XGBClassifier(base_score=None, booster=None, callbacks=None, | ||||
| colsample_bylevel=None, colsample_bynode=None, | ||||
| colsample_bytree=None, device='cpu', early_stopping_rounds=None, | ||||
| enable_categorical=False, eval_metric=None, feature_types=None, | ||||
| feature_weights=None, gamma=None, grow_policy=None, | ||||
| importance_type=None, interaction_constraints=None, | ||||
| learning_rate=0.4, max_bin=None, max_cat_threshold=None, | ||||
| max_cat_to_onehot=None, max_delta_step=None, max_depth=9, | ||||
| max_leaves=None, min_child_weight=None, missing=nan, | ||||
| monotone_constraints=None, multi_strategy=None, n_estimators=300, | ||||
| n_jobs=None, num_parallel_tree=None, ...) | 0.857942 | 0.283071 | 0.841234 | 0.857942 |
| XGBClassifier(base_score=None, booster=None, callbacks=None, | ||||
| colsample_bylevel=None, colsample_bynode=None, | ||||
| colsample_bytree=None, device='cpu', early_stopping_rounds=None, | ||||
| enable_categorical=False, eval_metric=None, feature_types=None, | ||||
| feature_weights=None, gamma=None, grow_policy=None, | ||||
| importance_type=None, interaction_constraints=None, | ||||
| learning_rate=0.1, max_bin=None, max_cat_threshold=None, | ||||
| max_cat_to_onehot=None, max_delta_step=None, max_depth=11, | ||||
| max_leaves=None, min_child_weight=None, missing=nan, | ||||
| monotone_constraints=None, multi_strategy=None, n_estimators=500, | ||||
| n_jobs=None, num_parallel_tree=None, ...) | 0.85906 | 0.288716 | 0.84354 | 0.85906 |
xgb.XGBClassifier(n_estimators=400,learning_rate=0.1, subsample=0.75, max_depth=9, device='cpu').fit(X_cat_train_resampled, y_cat_train_resampled)3. Model Combination (Ensembling)
We chose to ensemble to improve the accuracy of the the outcomes. Since the dataset heavily relies on text data we combined the MLPClassifier which works well with unstructured text data and XGBoost which is strong on structured data to enhance performance.
This would ensure the margin of error is minimalized. This approach is also a better fit for large data sets to account for varying data patterns. It will help with achieving great accuracy with better generalization. Both of these models help with generalization and performance within large data sets.
For the ensemble process we took the probabilities from both models instead of hard predictions. A meta classifier using Logistic Regression was created. We then combined the probabilities from the MLP Classifier and the XGBoost Classifier into a single dataset (X_meta_test) which was used to train and evaluate the meta-classifier.
# get probability outputs from both models
mlp_probs = clf.predict_proba(X_test)
xgb_probs = xgb_clf.predict_proba(X_cat_test_scaled)
#Create meta-training set (avoid data leakage)
X_meta_train, X_meta_test, y_meta_train, y_meta_test = train_test_split(
np.column_stack((mlp_probs, xgb_probs)), y_test, test_size=0.5, random_state=42
)
#create meta classifer using Logistic Regression
meta_clf = LogisticRegression()
meta_clf.fit(X_meta_train, y_meta_train)
#Evaluate on the meta validation set
X_meta_test = np.column_stack((clf.predict_proba(X_test), xgb_clf.predict_proba(X_cat_test_scaled)))
meta_preds = meta_clf.predict(X_meta_test)
metric = evaluate_model(meta_clf, X_meta_test, y_test)
headers = ["Model", "Accuracy", "Kappa", "Precision", "Recall"]
markdown_table = tabulate([metric], headers=headers, tablefmt="github")
print(markdown_table)| Model | Accuracy | Kappa | Precision | Recall |
|---|---|---|---|---|
| LogisticRegression() | 0.975951 | 0.715546 | 0.980566 | 0.975951 |
Model Eval
###Confusion Matrix
The ensemble model's confusion matrix below shows the following performance metrics:
- True Negatives (TN): 3,375 -- Non-fraudulent jobs correctly classified.
- False Positives (FP): 20 -- Non-fraudulent jobs misclassified as fraudulent.
- False Negatives (FN): 66 -- Fraudulent jobs misclassified as non-fraudulent.
- True Positives (TP): 115 -- Fraudulent jobs correctly classified.
###Evaluation Metrics
- Accuracy: 97.6% -- The model correctly classifies job postings in most cases.
- Recall: 97.6% -- The model captures 97.6% of all fraudulent job postings.
##Comparison The final ensemble model performed better than the previous models (MLP Classifier, XGBoost and Logistic Regression). It produced a higher accuracy and recall score when compared to the other models.
###Confusion Matrix
import matplotlib.pyplot as plt
display = ConfusionMatrixDisplay.from_estimator(
meta_clf,
X_meta_test,
y_test,
cmap=plt.cm.Blues,
values_format=".2f",
)
display.ax_.set_title("Meta Classifier Confusion Matrix")
plt.show()
plt.show()
plt.savefig('meta_confusion_matrix.png')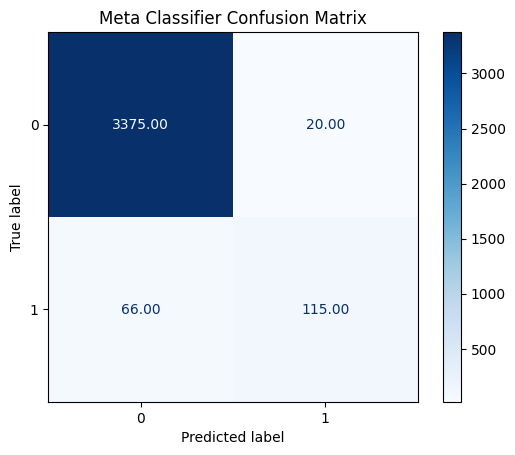
##Implications of Model Predictions False Positives (20 cases) -- Jobs incorrectly flagged as fraudulent
Impact: Some legitimate job postings are being flagged as fraudulent, potentially harming job seekers or recruiters who rely on job listings for job seeking and hiring. This pose this risk of if too many false positives occur, companies may lose trust in the platform, and job seekers might miss out on genuine opportunities. Further fine tuning the model's threshold or adding post-processing rules could reduce this risk.
False Negatives (66 cases) -- Fraudulent jobs slipping through
Impact: These are the most critical errors in scam and fraud detection as they allow fraudulent job postings to appear legitimate which can led job seekers being exploited or financial loss by rcruitment agencies
This pose the risk of the model or platform its applied on losing credibility and user trust may be negatively affected if fraudulent jobs continue to get posted. Since recall is crucial in fraud detection, further model enhancements such as adjusting the decision threshold to favor recall over precision might help catch more fraudulent listings at the expense of more false positives.
Test
def predict_fraudulent_job(job_data, tokenizer, bert_model, target_encoder, scaler, mlp_model, xgb_model, meta_model):
"""
Predict whether a job posting is fraudulent using the ensemble model.
Args:
job_data (dict): A dictionary with job details (title, description, etc.)
tokenizer: BERT tokenizer.
bert_model: Pre-trained BERT model.
target_encoder: Fitted target encoder for categorical features.
scaler: Fitted StandardScaler.
mlp_model: Trained MLP model.
xgb_model: Trained XGBoost model.
meta_model: Trained meta-classifier.
Returns:
dict: Fraud probability and final classification.
"""
#Extract Text Features & Generate BERT Embeddings
job_text = " ".join([job_data[col] for col in ['title', 'company_profile', 'description', 'requirements', 'benefits'] if col in job_data])
encoding = tokenizer(job_text, truncation=True, padding=True, return_tensors='pt')
with torch.no_grad():
input_ids = encoding['input_ids'].to(xm.xla_device())
attention_mask = encoding['attention_mask'].to(xm.xla_device())
bert_output = bert_model(input_ids, attention_mask=attention_mask)
job_embedding = bert_output.pooler_output.cpu().numpy()
#Encode & Normalize Categorical Features
categorical_data = pd.DataFrame([job_data])
categorical_encoded = target_encoder.transform(categorical_data[categorical])
categorical_scaled = scaler.transform(categorical_encoded)
#Get Predictions from Base Models
mlp_probs = mlp_model.predict_proba(job_embedding)
xgb_probs = xgb_model.predict_proba(categorical_scaled)
#Combine Outputs & Predict with Meta-Classifier
stacked_probs = np.column_stack((mlp_probs, xgb_probs))
ensemble_probs = meta_model.predict_proba(stacked_probs)[:, 1] # Probability of fraudulent job
#Convert to Final Prediction (0 = Real, 1 = Fake)
prediction = (ensemble_probs >= 0.5).astype(int)
return {"fraud_probability": float(ensemble_probs), "prediction": int(prediction)}job_data = {"title": "Software Engineer", "company_profile": "Tech startup", "description": "Looking for Python developer", "requirements": "Python, ML experience", "benefits": "Flexible hours", "employment_type": "Full-time", "required_experience": "Mid", "required_education": "Bachelor", "industry": "Tech", "function": "Engineering", "department":'Infortmation Technology', "salary_range": "200000-300000" }
bert_model = BertModel.from_pretrained('bert-base-uncased')
bert_model.to(xm.xla_device())
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
target_encoder = ce.TargetEncoder(cols=categorical)
target_encoder.fit_transform(jobs[categorical], jobs['fraudulent'])
scaler = StandardScaler()
scaler.fit(target_encoder.transform(jobs[categorical]))
predict_fraudulent_job(job_data, tokenizer, bert_model, target_encoder, scaler, clf, xgb_clf, meta_clf)Save models (Optional)
import joblib
import torch
# Save BERT tokenizer and model
tokenizer.save_pretrained("saved_models/bert_tokenizer")
torch.save(model.state_dict(), "saved_models/bert_model.pth")
# Save categorical feature encoders
joblib.dump(target_encode, "saved_models/target_encoder.pkl")
joblib.dump(scaler, "saved_models/scaler.pkl")
# Save classifiers
joblib.dump(clf, "saved_models/mlp_classifier.pkl")
joblib.dump(xgb_clf, "saved_models/xgboost_classifier.pkl")
joblib.dump(meta_clf, "saved_models/meta_classifier.pkl")
print("All models saved successfully!")
!zip -r /content/saved_models.zip /content/saved_models
Reference
-
Akram, Natasha & Irfan, Rabia & Al-Shamayleh, Ahmad & Kousar, Adila & Qaddos, Abdul & Imran, Muhammad & Akhunzada, Adnan. (2024). Online Recruitment Fraud (ORF) Detection Using Deep Learning Approaches. IEEE Access. PP. 1-1. 10.1109/ACCESS.2024.3435670.
-
Brownlee, J. (2020). How to tune the number and size of decision trees with XGBoost in python. MachineLearningMastery.com. https://machinelearningmastery.com/tune-number-size-decision-trees-xgboost-python/
-
Brownlee, J. (2020). Tune learning rate for gradient boosting with XGBoost in python. MachineLearningMastery.com. https://machinelearningmastery.com/tune-learning-rate-for-gradient-boosting-with-xgboost-in-python/
-
Harode, R. (2020). XGBoost: A deep dive into boosting. Medium. https://medium.com/sfu-cspmp/xgboost-a-deep-dive-into-boosting-f06c9c41349